Let`s Encrypt 무료 인증서 설치 방법
Let’s Encrypt란?
Lets’ Encrypt는 HTTPS를 사용하기 위해 SSL을 구매해야 하는 부분이 HTTPS 보급에 방해된다고 생각해서 SSL을 무료로 제공해서 HTTPS를 보급하기 위해 작년 말에 만들어졌다.
초기에는 Mozilla, Cisco, Akamai, EFF, id entrust 등이 모여서 ISRG(Internet Security Research Group)라는 새로운 SSL 인증기관을 만들어서 올해 SSL을 무료로 제공하겠다고 발표했다.
지금은 이 Lets’ Encrypt에 Facebook, 워드프레스를 만드는 Automattic, shopify 등 많은 회사가 스폰서로 참여하고 있다.
Getting the Let’s Encrypt client
let’s encrypt는 web server에 ssl 설정을 가장 단순하게 자동적으로 설정할 수 있다.
이를 위해서 client를 받아야되는데 github repository(https://github.com/certbot/certbot)에서 다운 받을 수 있다. git이 설치되어 있지 않다면 아래 명령어로 설치를 진행한다.
$ sudo apt-get install git
$ sudo yum install git
git 설치가 되었다면 아래 명령어로 다운 받는다.
$ git clone https://github.com/letsencrypt/letsencrypt
다운되어진 letsencrypts 디렉토리로 이동한다.
$ cd letsencrypt
client와 함께 제공되는 letsencrypt-auto 스크립트를 구동하여 인증서를 생성할 수 있다. 인증서 생성은 관리자 권한이 필요하기에 sudo를 사용한다. 구동하기 전 let’s encrypt 의 인증 방식인 Standalone plugin 은 서버 인증을 위해서 80포트를 이용하기 때문에 nginx, apache 와 같이 80 포트를 이용하는 서비스가 있다면 서비를 일시적으로 중지해야 한다.
$ sudo /etc/init.d/nginx restart
$ sudo netstat -nlp | grep 80
80 포트로 운영되는 서비스가 없는 것을 확인하였다면 아래 스크립트를 실행하여 인증서를 생성한다.
$ sudo ./letsencrypt-auto certonly --standlone
관련 패키지가 설치된 뒤 이메일 주소를 입력하는 창을 확인 할 수 있다. 긴급 공지나 키를 복구하기 위해 사용되는 이메일 주소를 입력한다.
이용약관에 동의한다. Agree Enter
마지막으로 도메인 주소를 입력한다. 도메인 주소는 FQDN 표기법으로 입력한다.
정상적으로 생성이 완료될 경우 congratulations! 메시지와 함께 인증서가 생성된 것을 확인할 수 있다. 아래 내용을 보면 인증서가 2016-10-20 에 만료된다고 나와 있다. Let’s encrypt의 인증서는 90일 동안 유효한 인증서이므로 90일마다 새로 갱신을 해야 한다. 자동 갱신 방법에 대해서는 아래에서 추가하도록 하겠다.
IMPORTANT NOTES:
- Congratulations! Your certificate and chain have been saved at
/etc/letsencrypt/live/example.com/fullchain.pem. Your cert
will expire on 2016-10-20. To obtain a new or tweaked version of
this certificate in the future, simply run letsencrypt-auto again.
To non-interactively renew *all* of your certificates, run
"letsencrypt-auto renew"
- If you like Certbot, please consider supporting our work by:
Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
Donating to EFF: https://eff.org/donate-le
인증서가 생성된 해당 경로로 이동하면 아래와 같은 인증서를 볼 수 있다.
- cert.pem : 도메인 인증서
- chain.pem : Let’s Encrypt chain 인증서
- fullchain.pem : cert.pem 과 chain 인증서 합본
- privkey.pem : 개인키
Nginx SSL 설정
nginx 웹서버에 경우 fullchain.pem과 privkey.pem 인증서를 사용한다.
신규 vhost 파일을 생성한다.
$ sudo vi /etc/nginx/site-available/example
443 포트를 listen 하며 server_name에 도메인 주소를 입력합니다. 아래 설정을 참고하여 생성한다.
listen 443 ssl;
server_name example.com www.example.com;
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_prefer_server_ciphers on;
ssl_ciphers 'EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH';
location ~ /.well-known {
allow all;
}
추가적으로 80 포트에서 들어오는 주소를 443 https로 보내주는 설정을 추가할 수 있다.
server {
listen 80;
server_name example.com;
return 301 https://$host$request_uri;
}
설정이 완료되었다면 nginx configtest 를 진행한 뒤 문제가 없을 경우 restart하여 설정을 적용한다.
$ sudo /etc/init.d/nginx configtest
Testing nginx configuration: nginx.
$ sudo /etc/init.d/nginx restart
Let’s Encrypt 인증서 자동 갱신
위에서 정상적으로 인증서를 발급하게 되면 만료기간이 언제인지 확인 할 수 있다. 작성한 내용이지만 90일 동안 인증서가 유효하기에 90일이 지나면 새로 갱신을 해야 한다. 우선 갱신하는 방법은 아래와 같다.
위에서 받은 client 폴더로 이동하여 letsencrypt-auto 스크립트로 갱신이 가능하다.
$ sudo ./letsencrypt-auto renew
아래와 같이 스크립트를 만들어 매달 1일날 해당 스크립트를 구동하여 자동으로 갱신이 되도록 crontab에 설정하였다. 유효기간이 30일 남았을 때부터 갱신이 가능하기에 매주 일요일 새벽 2시 해당 스크립트를 구동한다.
# vi /etc/nginx/letsencrypt/renew.sh
#!/bin/sh
/etc/init.d/nginx stop
if ! /etc/nginx/letsencrypt/letsencrypt-auto renew > /var/log/letsencrypt-renew.log 2>&1 ; then
echo Automated renew failed;
cat /var/log/letsencrypt-renew.log
exit 1
fi
/etc/init.d/nginx start
# crontab -l
0 2 * * 0 /etc/nginx/letsencrypt/renew.sh
DHCP Relay를 이용하여 여러 네트워크 대역의 DHCP 서비스
개요
일반적으로 DHCP는 동일 네트워크(subnet)에서 작동한다. Client가 DHCP 요청시 dhcp discover message를 broadcast로 보내기때문이다. 그래서 다른 네트워크(subnet)의 dhcp dicover message는 dhcp server로 전달되지 않는다. 그럼 여러 네트워크에서 dhcp를 사용하려면 각 네트워크 대역마다 dhcp server를 두어야만 하는가? 이때 dhcp relay를 이용하면 하나의 dhcp server에서 여러 네트워크를 서비스할 수 있다. dhcp relay는 dhcp 요청을 다른 네트워크 대역에 있는 dhcp server로 중계(relay)하는 역할을 한다. 각 대역마다 dhcp relay를 두어 하나의 dhcp server로 relay하게끔 설정하면 된다.
구성
ntwork vendor사마다 이름은 다르지만 relay 기능들이 존재한다. (예를 들면 cisco의 ip-helper) 우리는 debian jessie os 위에 isc dhcp(https://www.isc.org/downloads/dhcp/)를 얹어 구성할 것이다. 네트워크의 구성은 아래의 그림과 같다.
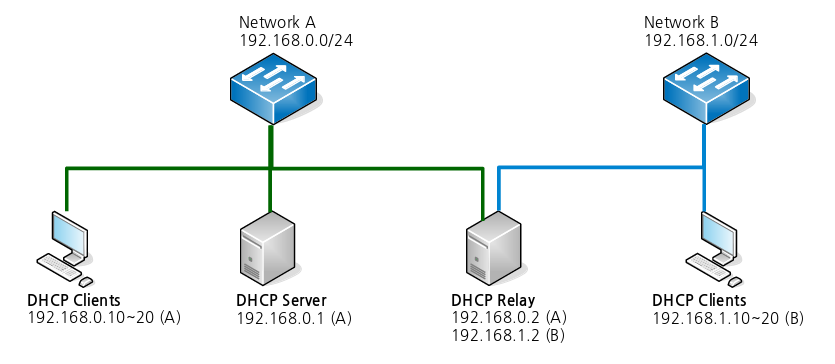
- A 네트워크(192.168.0.0/24)와 B 네트워크(192.168.1.0/24), 총 2개의 네트워크 구성이다.
- A 네트워크에 DHCP Server가 구동된다.
- DHCP Relay는 B 네트워크의 DHCP 요청을 A 네트워크의 DHCP Server로 중계할것이다.
DHCP Server 설치/설정
DHCP Server에서 아래와 같이 isc-dhcp-server package를 설치한다.
# apt-get install isc-dhcp-server
DHCP 설정은 다른 옵션값을 배제하고 최대한 단순하게 했다. 네트워크의 range만 설정했다.
# vi /etc/dhcp/dhcpd.conf
subnet 192.168.0.0 netmask 255.255.255.0 {
range 192.168.0.10 192.168.0.20;
}
subnet 192.168.1.0 netmask 255.255.255.0 {
range 192.168.1.10 192.168.1.20;
}
DHCP 서버는 A 네트워크 뿐아니라 B 네트워크의 DHCP 설정값을 모두 가지고 있다. DHCP Relay에 DHCP Server로 전달는 설정뿐 별다른 설정이 없다. isc-dhcp-server를 설치한적이 있다면 별다른게 없음을 알수있다. 자기 네트워크이외 다른 네트워크의 설정만 추가되었을 뿐이다.
이제 dhcp daemon를 restart한다.
# systemctl restart isc-dhcp-server
# ps -ef|grep dhcrelay
DHCP relay 설치/설정
DHCP Relay Server에서 isc-dhcp-relay package를 설치한다.
# apt-get install isc-dhcp-relay
이제 DHCP Server로 relay하는 설정을 진행한다.
# vi /etc/default/isc-dhcp-relay
SERVERS="192.168.0.1"
INTERFACES="eth0 eth1"
- SERVERS : relay할 서버를 설정한다. 보면 S가 붙어있다. 여러개의 DHCP 서버로 relay 가능하다. (space-seperated)
- INTERFACES : relay service를 할 interface를 설정한다. Manpage에는 나와있지 않지만 추가로 DHCP와 통신할 interface도 넣어야한다. 따라서 2개의 interface를 모두 설정하였다.
이제 relay daemon를 restart한다.
# systemctl restart isc-dhcp-relay
# ps -ef|grep dhcrelay
DHCP Client 확인
이제 DHCP Client에서 제대로 IP를 받아오는지 확인하면 된다. 제대로 받아왔다면 dhcp server에서는 아래와 같은 log를 확인할수 있을것이다.
# tail /var/log/daemon.log
dhcpd: DHCPDISCOVER from 00:16:3e:ee:92:cd via 192.168.0.2
dhcpd: DHCPOFFER on 192.168.1.10 to 00:16:3e:ee:92:cd via 192.168.0.2
dhcpd: DHCPREQUEST for 192.168.1.10 (192.168.0.1) from 00:16:3e:ee:92:cd via 192.168.0.2
dhcpd: DHCPACK on 192.168.1.10 to 00:16:3e:ee:92:cd via 192.168.0.2
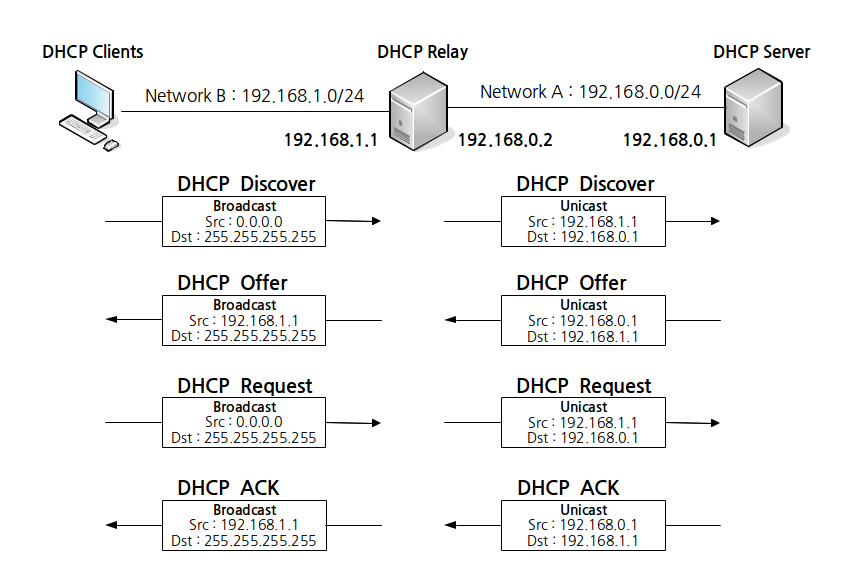
작동 방법
DHCP는 Discover, Offer, Request, Ack 4개의 Message로 구성되어 있다. (참조 : http://www.netmanias.com/ko/post/blog/5348/dhcp-ip-allocation-network-protocol/understanding-the-basic-operations-of-dhcp) 그럼 궁금증이 생긴다. Discover와 Request같은 broadcast는 relay server가 받은 그대로 다시 broadcast하는가? DHCP Relay는 DHCP Server와 unicast로만 message를 주고 받는다. 그래서 위의 SERVERS 설정으로 주고 받을 ip를 설정한것이다.
- client의 dhcp discover message는 broadcast로 dhcp relay에 도착된다. dhcp relay는 이 discover를 unicast로 dhcp server에 전달한다.
- dhcp server는 offer message를 unicast로 dhcp relay에 전달한다. dhcp relay는 이 offer를 broadcast로 client에 전달한다.
Trouble Shutting
만약 문제가 발생할 경우 -q 옵션을 지워 quite mode를 끄고, -f 옵션으로 daemon을 foreground로 띄우는게 좋다. 나오는 message를 잘 확인해보자. 물론 man page는 필수다. (man dhcpd, man dhcrelay)
xen에서의 checksum error
위의 dhcp log의 mac을 보면 눈치했을수도 있지만, 위 테스트를 xen에서 진행하였다. 그런데 relay에서 전달된 message가 dhcp server에서 받지 못하는 현상이 나타났다. 원인은 dhcp server nic의 udp checksum error였다. vm의 nic module을 vif에서 e1000(emulated)로 변경후엔 문제없이 진행되었다. 구글링을 해보니 대부분 workaround로 ethool을 이용하여 checksum를 끄라고 나와있는데 내 경우엔 작동되지 않았다.
SR-IOV on XEN
개요
SR-IOV?
- SR-IOV : Single Root-Input Output Virtualization
- 물리 PCIe 장치를 여러 개의 PCIe 장치로 보이게 하는 PCI-SIG(http://www.pcisig.com/)에서 제정한 표준 스펙문서
- SR-IOV는 Physical functions(PFs)와 Virtual Functions(VFs)로 나누어짐
- PFs : Full-featured PCIe functions (configuration and data functions)
- VFs : lightweight PCIe functions (only data functions)
- PCIe 장치는 최대 256 VFs까지 가질수 있으나 각 VF는 실제 하드웨어 리소스가 필요하기 때문에 실제적인 최대값은 64VFs
- 제한점
- VF는 PF와 같은 장치로만 사용 가능
- VF는 PF와 같은 네트워크 대역이어야 함
- 조건
- SR-IOV를 지원하는 mainboard(bios)와 CPU (intel VT-D or AMD iommu)
- SR-IOV를 지원하는 NIC (e.g. Intel 82576)
- SR-IOV를 지원하는 Hypervisor, Dom0, DomU
Xennet vs. SR-IOV
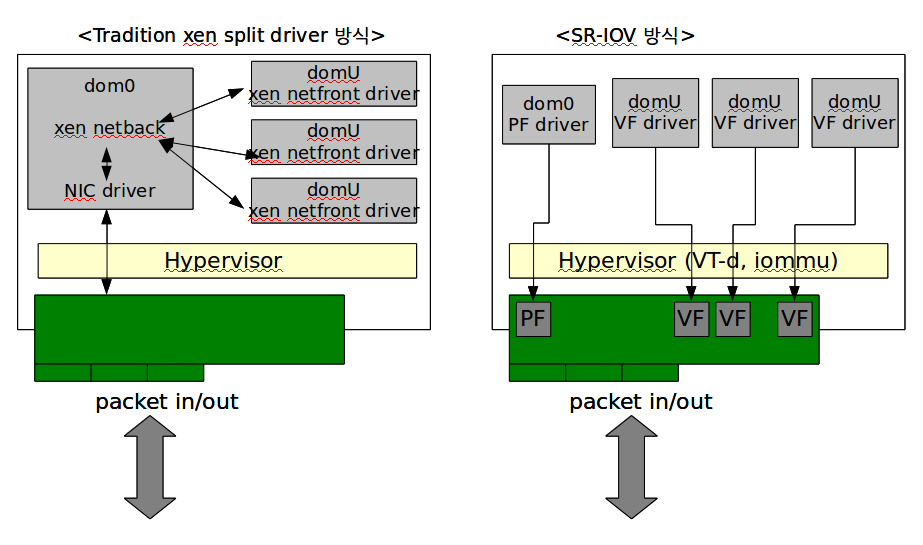
설정
지원확인
먼저 서버의 CMOS 에 들어가서 Intel VT-d 가 켜져 있는지 확인하라. VT-d 가 없으면 SR-IOV를 사용할 수 없다.
dom0# xm dmesg
(XEN) Intel VT-d Snoop Control enabled.
(XEN) Intel VT-d Dom0 DMA Passthrough not enabled.
(XEN) Intel VT-d Queued Invalidation enabled.
(XEN) Intel VT-d Interrupt Remapping enabled.
(XEN) Intel VT-d Shared EPT tables not enabled.
(XEN) I/O virtualisation enabled
NIC 역시 SR-IOV를 지원해야 한다. 아래 Intel 82576 NIC은 SR-IOV를 지원하는 NIC이다. linux module 이름은 igb 이다.
dom0# modinfo igb
filename: /lib/modules/2.6.32.39-175.xendom0.el6.x86_64/kernel/drivers/net/igb/igb.ko
version: 1.3.16-k2
license: GPL
description: Intel(R) Gigabit Ethernet Network Driver
author: Intel Corporation, <e1000-devel@lists.sourceforge.net>
srcversion: 67CCD4CBBFB5F99C69546C2
alias: pci:v00008086d000010D6sv*sd*bc*sc*i*
alias: pci:v00008086d000010A9sv*sd*bc*sc*i*
alias: pci:v00008086d000010A7sv*sd*bc*sc*i*
alias: pci:v00008086d000010E8sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Dsv*sd*bc*sc*i*
alias: pci:v00008086d000010E7sv*sd*bc*sc*i*
alias: pci:v00008086d000010E6sv*sd*bc*sc*i*
alias: pci:v00008086d00001518sv*sd*bc*sc*i*
alias: pci:v00008086d0000150Asv*sd*bc*sc*i*
alias: pci:v00008086d000010C9sv*sd*bc*sc*i*
depends: dca
vermagic: 2.6.32.39-175.xendom0.el6.x86_64 SMP mod_unload
parm: max_vfs:Maximum number of virtual functions to allocate per physical function (uint)
마지막 parm: 라인을 주목하자. 이것이 바로 SR-IOV의 기능을 설명한다. max_vfs option을 주어 몇 개의 VF를 만들지 설정할 수 있다.
Dom0 설정
GRUB_CMDLINE_LINUX_DEFAULT 에 pci_pt_e820_access=on, GRUB_CMDLINE_XEN_DEFAULT에 iommu=1 msi=1 추가하고 grub를 업데이트(update-grub)한다.
dom0# vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="quiet pci_pt_e820_access=on"
GRUB_CMDLINE_XEN_DEFAULT="dom0_mem=4G,max:4G iommu=1 msi=1"
dom0# update-grub
- iommu=1 : enables SR-IOV
- msi=1 : enables MSI-X interrupts
- pci_pt_e820_access=on : enables direct assignment of a PCIe device to a Virtual Machine
그리고 아래와 같이 modprobe를 설정한다. igb driver를 loading할때 7개의 VF를 생성하고,
dom0# vi /etc/modprobe.d/igb.conf
options igb max_vfs=7
dom0# vi /etc/modprobe.d/igbvf-blacklist.conf
blacklist igbvf
dom0# update-initramfs -k `uname -r` -t -u
- options igb max_vfs=7 : igb driver를 loading할 때 VF를 7개 생성
- blacklist igbvf : igbvf는 domU에서 VF를 사용하기 위해서 loading하는 module이다. 따라서 dom0에서는 blacklist에 올려놓아 loading하지 않도록 한다.
이제 SR-IOV 설정이 끝났다. 리부팅한다.
dom0# lspci |grep Eth
01:00.0 Ethernet controller: Intel Corporation 82575EB Gigabit Network Connection (rev 02)
01:00.1 Ethernet controller: Intel Corporation 82575EB Gigabit Network Connection (rev 02)
03:00.0 Ethernet controller: Intel Corporation 82576 Gigabit Network Connection (rev 01)
03:00.1 Ethernet controller: Intel Corporation 82576 Gigabit Network Connection (rev 01)
03:10.0 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.1 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.2 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.3 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.4 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.5 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.6 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:10.7 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.0 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.1 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.2 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.3 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.4 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
03:11.5 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
Virtual function이 14개 생성된 것을 볼 수 있다. 82576 NIC이 두 개이고, max_vfs=7으로 했으므로 2*7 = 14개 생성된 것이다. 이것은 dmesg에서 보다 더 잘 볼 수 있다.
dom0# dmesg |grep -i vfs
igb 0000:03:00.0: 7 vfs allocated
igb 0000:03:00.1: 7 vfs allocated
이제 domU가 PCIe 장치를 바로 사용할 수 있도록 설정하자.
dom0# vi /etc/modprobe.d/pciback.conf
alias pciback xen-pciback
options pciback hide=(03:10.0)(03:10.1)(03:10.2)(03:10.3)(03:10.4)(03:10.5)(03:10.6)(03:10.7)(03:11.0)(03:11.1)(03:11.2)(03:11.3)(03:11.4)(03:11.5)
위 내용은 pciback module을 올릴 때 VFs에 해당하는 장치를 숨긴다. 실제 module이름은 xen-pciback이고 alias로 pciback을 설정하였다. 그리고 hide option을 통해 VFs 장치를 나열하였다.
pciback module을 올려보자.
dom0# modprobe pciback
dom0# dmesg
....
[ 134.962573] pciback 0000:03:10.0: seizing device
[ 134.962583] pciback 0000:03:10.2: seizing device
[ 134.962592] pciback 0000:03:10.4: seizing device
[ 134.962597] pciback 0000:03:10.6: seizing device
[ 134.962602] pciback 0000:03:11.0: seizing device
[ 134.962607] pciback 0000:03:11.2: seizing device
[ 134.962612] pciback 0000:03:11.4: seizing device
[ 134.962617] pciback 0000:03:10.1: seizing device
[ 134.962621] pciback 0000:03:10.3: seizing device
[ 134.962627] pciback 0000:03:10.5: seizing device
[ 134.962632] pciback 0000:03:10.7: seizing device
[ 134.962636] pciback 0000:03:11.1: seizing device
[ 134.962641] pciback 0000:03:11.3: seizing device
[ 134.962646] pciback 0000:03:11.5: seizing device
[ 134.962707] pciback 0000:03:11.5: enabling device (0000 -> 0002)
[ 134.962750] pciback 0000:03:11.3: enabling device (0000 -> 0002)
[ 134.962787] pciback 0000:03:11.1: enabling device (0000 -> 0002)
[ 134.962823] pciback 0000:03:10.7: enabling device (0000 -> 0002)
[ 134.962865] pciback 0000:03:10.5: enabling device (0000 -> 0002)
[ 134.962908] pciback 0000:03:10.3: enabling device (0000 -> 0002)
[ 134.962944] pciback 0000:03:10.1: enabling device (0000 -> 0002)
[ 134.962978] pciback 0000:03:11.4: enabling device (0000 -> 0002)
[ 134.963011] pciback 0000:03:11.2: enabling device (0000 -> 0002)
[ 134.963045] pciback 0000:03:11.0: enabling device (0000 -> 0002)
[ 134.963080] pciback 0000:03:10.6: enabling device (0000 -> 0002)
[ 134.963116] pciback 0000:03:10.4: enabling device (0000 -> 0002)
[ 134.963150] pciback 0000:03:10.2: enabling device (0000 -> 0002)
[ 134.963183] pciback 0000:03:10.0: enabling device (0000 -> 0002)
[ 134.963240] xen-pciback: backend is vpci
이제 domU가 SR-IOV를 사용할 준비가 되었다. 다음 명령으로 어느 pci장치를 이용할 수 있는 지 알 수 있다.
dom0# xm pci-list-assignable-devices |sort -n (xl pci-assignable-list)
xl pci-list-assignable-devices
0000:03:10.0
0000:03:10.1
0000:03:10.2
0000:03:10.3
0000:03:10.4
0000:03:10.5
0000:03:10.6
0000:03:10.7
0000:03:11.0
0000:03:11.1
0000:03:11.2
0000:03:11.3
0000:03:11.4
0000:03:11.5
DomU 설정
domU config파일에 pci=[‘03:10.0’] 을 추가하자.
#vif=["mac=00:16:3e:13:d1:31,bridge=xenbr0"]
pci=["03:10.0"]
vif 부분을 주석처리하였다. 즉, xen netback을 사용하지 않고 pci through 장치를 사용하겠다는 것이다.
VM을 구동하여 정상적으로 잡혀 있는지 확인한다.
domU# lspci
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma] (rev 02)
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.1 IDE interface: Intel Corporation 82371SB PIIX3 IDE [Natoma/Triton II]
00:01.2 USB Controller: Intel Corporation 82371SB PIIX3 USB [Natoma/Triton II] (rev 01)
00:01.3 Bridge: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 01)
00:02.0 VGA compatible controller: Technical Corp. Device 1111
00:03.0 Unassigned class [ff80]: XenSource, Inc. Xen Platform Device (rev 01)
00:05.0 Ethernet controller: Intel Corporation 82576 Virtual Function (rev 01)
맨 마지막 라인을 보면 pci passthrough가 된 것을 볼 수 있다. intel 82576 NIC의 VF가 보인다.
이제 DomU의 network를 설정하면 된다.
troubleshooting
DomU Kernel Version
Linux Kernel 2.6.37부터 PCI frontend driver가 SR-IOV를 지원한다.
Dom0에서 VF에 Mac 부여
VF에 Mac주소를 할당하지 않고 VM을 부팅하면 VM이 mac 주소가 없다고 하여 NIC자체를 거부한다. 따라서 dom0에 아래와 같이 할당할 VF에 대한 Mac을 설정해주고 domu를 부팅해야 한다.
dom0# ip link set eth0 vf 0 mac 00:1e:67:65:93:01
이전과 이렇게 다른 이유는 xen version 차이(4.1.4 vs. 4.4-unstable) 때문일 것이다.
특정 서버의 경우 iommu 옵션 변경 필요
일부 수퍼마이크로 서버의 경우 Xen grub option에 iommu=1 로 주고 부팅하면 다음과 같은 에러가 발생한다.
(XEN) DMAR_IQA_REG = 7f79d000
(XEN) DMAR_IQH_REG = 0
(XEN) DMAR_IQT_REG = 20
(XEN)
(XEN) ****************************************
(XEN) Panic on CPU 0:
(XEN) queue invalidate wait descriptor was not executed
(XEN) ****************************************
(XEN)
(XEN) Reboot in five seconds...
이 경우 queue invalidate를 하지 않도록 수정해야 한다. iommu=no-qinval을 주고 부팅하면 된다.
References
- https://communities.intel.com/community/wired/blog/2010/03/01/setting-up-red-hat-54-xen-for-sr-iov-using-the-intel-82576-gbe
- https://wiki.xen.org/wiki/RHEL5_CentOS5_Xen_Intel_SR-IOV_NIC_Virtual_Function_VF_PCI_Passthru_Tutorial
- http://www.alexonlinux.com/msi-x-the-right-way-to-spread-interrupt-load
- https://en.wikipedia.org/wiki/Message_Signaled_Interrupts
- http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/Documentation/PCI/MSI-HOWTO.txt?id=HEAD
- https://communities.intel.com/thread/29944
- http://wiki.xen.org/wiki/RHEL5_CentOS5_Xen_Intel_SR-IOV_NIC_Virtual_Function_VF_PCI_Passthru_Tutorial#Xen_SR-IOV_VF_PCI_passthru_to_CentOS_6_PV_domU
DHCP 임대 시간
개요
DHCP Client는 DHCP Server로부터 IP를 할당받을때 임대시간(lease time)도 할당받는다. 임대시간(lease time)은 DHCP Client가 IP를 사용할수 있는 기간이다. 임대시간이 끝나면 해당 IP는 DHCP Server로 반환되며, Client는 IP가 미할당된 상태가 된다. 임대시간이 만료(expire)된다면 DHCP Client는 다시 DHCP Broadcast로 DHCP Dicover를 진행할까? DHCP는 이와 관련하여 임대 갱신(lease renewal)의 프로세스가 존재한다. 임대 만료가 되기전 주기적으로 임대시간을 연장하는 작업을 진행한다. 이 임대 갱신 과정으로 인해 한번 임대한 IP 주소를 지속적으로 사용할수 있게 된다.
임대 갱신 과정
아래의 경우는 임대시간(lease time)을 8시간으로 할당한 예이다. (8은 시간 계산의 편의성을 위해서다.)
Renewal (T1)
DHCP Server로부터 8시간동안 임대시간을 할당받았다면, DHCP Client는 4시간이 지난후에(임대시간 1/2 지점, 50%) Renewal을 시도한다. 만료(expire)시간을 늘리는것이다. 이 Renewal은 Discover, Offer과정을 진행하지 않는다. 이미 DHCP 서버의 주소를 파악한 상태이기에 Request, ACK 과정을 DHCP Server와 Unicast로 진행한다. 따라서 DHCP Server와 정상적으로 통신이 된다면, DHCP 만료시간은 4시간 마다 재갱신이 된다. 만약 DHCP Server가 죽거나 통신이 끊겨 Renewal이 실패했다면? Rebinding이 있다.
Rebinding (T2)
Rebinding은 임대의 7/8 지점(87.5%)인 7시간이 지난뒤에 진행된다. 이때는 해당 DHCP로 Unicast가 아닌 Broadcast로 Request, ACK 과정을 진행한다. 만약 응답할 서버가 없다면 DHCP Dicover를 broadcast로 날려 새로운 DHCP Server를 찾게된다. 이때는 초기 DHCP 요청과 동일한 과정으로 진행된다. 만약 이 Rebinding도 실패한다면? 만료시간이 끝나면 IP가 없는 상태가 된다.
isc dhcp server에서의 설정
isc-dhcp-server에서는 lease time관련하여 3개의 옵션이 존재한다.
- default-lease-time : 말그대로 기본 임대시간(초)이다. DHCP Client(linux의 경우라면 dhclient)에 따라 DHCP 요청시 lease time을 설정할수 있는데, 이때 lease time을 지정하지 않을 경우 이 시간으로 임대시간을 할당한다.
- max-lease-time : 최대 임대 시간(초)이다. Client의 lease time 요청이 이 max-lease-time보다 클 경우 할당되게 된다.
- min-lease-time : 최소 임대 시간(초). max와 반대로 client의 lease time이 min-lease-time보다 작을경우 할당되게 된다.
3개의 옵션 모두 기한없이 임대하고 싶을경우 -1을 설정하면 된다. 그러나 -1로 설정했을때 client에서 lease-time은 4294967295초가 할당되었다. 그러니까 -1은 임대 시간의 최대치, 즉 2^32임을 알수 있다. 년(year)로 계산하면 136년이 조금 넘는다. 68년에 한번씩 renew 작업을 하는꼴이니 사실상 영구임대로 봐도 될듯 싶다.
dhcp client에서 임대 시간 확인
linux라면 /var/lib/dhcp/dhclient.leases 파일에서 확인할수 있다.
# tail /var/lib/dhcp/dhcpclient.leases
....
option dhcp-lease-time 28800;
renew 4 2016/11/03 21:44:23;
rebind 5 2016/11/04 00:51:05;
expire 5 2016/11/04 01:51:05;
renew, rebind, expire에서 날짜 앞에 숫자는 요일(day of week)이다. 1을 월요일로 시작하여 4는 목, 5는 금이다.
windows는 임대 시작과 만료 시간만 확인할수 있다.
C:\> ipconfig /all
....
임대 시작 날짜 . . . . . . . : 2016년 11월 3일 목요일 오전 10:56:44
임대 만료 날짜 . . . . . . . : 2016년 12월 11일 월요일 오전 12:22:44
DHCP로 hostname 설정하기
DHCP로 client의 hostname을 설정할수 있는 팁이다. dhclient의 hook을 이용하면 된다.
isc-dhcp-server 설정
option host-name으로 설정할 hostname을 지정한다.
# vi /etc/dhcp/dhcpd.conf
...
...
...
host test {
hardware ethernet 00:16:3E:CF:E6:3A;
fixed-address 192.168.24.151;
option host-name webserver01;
}
Linux Client(dhclient)에서 설정
dhcp request시 host-name을 요청하게 설정해야한다. debian wheezy, jessie는 default로 설정되어 있어 수정할 필요가 없었다. 아마 대부분의 linux에서는 기본으로 설정되어 있지 않을까 싶다. request의 설정부분에 host-name을 추가하도록 하자.
# vi /etc/dhcp/dhclient.conf
request ..., ..., host-name, ...
이제 ip를 할당받고 난뒤 dhcp 과정을 종료할때 수행되는 dhclient-exit-hooks에 hostname을 설정하는 스크립트를 넣으면 된다.
# vi /etc/dhcp/dhclient-exit-hooks.d/set_hostname
hostname $new_host_name
new_host_name이라는 변수에 dhcp-server에서 할당받은 hostname이 기록된다. 이를 hostname command로 처리한것이다.
이제 dhcp request를 날려 정상적으로 hostname이 변경되는지 확인해본다.
# dhclient -v eth0
# hostname
webserver01
정상적으로 변경되었음을 확인할수 있다. 그러나 더 처리할 사항은 남아있다. /etc/hosts, /etc/hostname등도 같이 수정해야 할것이다. sed등을 이용하여 스크립트를 작성하면 된다. 배포판마다 hostname 설정 파일이 다르니 조심하자. (centos/rhel의 경우 /etc/sysconfig/networks 파일의hostname을 변경해야한다.)
Windows에서의 설정
안타깝게도 windows에서는 host-name을 설정할 수 없다. dhcp client가 request시 host-name을 요청하게 해야하는데 windows는 아예 이 관련 옵션이 없다고 한다. 따라서 dhcp server에서 hostname을 설정한들 아무 의미가 없다.
coredump를 이용하여 kernel crash에 대응하기
구동중인 OS가 갑자기 kernel panic등으로 crash되었을때, crashdump를 이용하면 crash되었을때의 memory를 file로 dump할 수 있다. system log등에 아무런 기록이 없을때 이 crashdump 파일은 문제 원인을 파악하는데 큰 도움을 준다.
kernel(OS) crash의 원인
먼저 kernel crash의 원인이 살펴보자. crash는 kernel(os)이 스스로 제어/복구 할 수 없는 상황이 되었을때 발생한다. kernel이 error(event)를 감지하였을때 Linux의 경우 kernel panic, Windows의 경우 BSOD(Blue Screen Of Death)등을 console에 띄우고, 더이상 진행할 수 없으므로 장렬히 전사(hang/reboot)하게 되는것이다. 원인은 매우 다양하다.
- RAM 불량 : 물리적으로 메모리가 불량인 경우인데, 경험적으론 생각보다 꽤 많이 발생했다. 모든 프로그램이 메모리에 적제되니 특정 경우와 관련없이 random하게 발생한다. 이 경우 memtest86+(http://www.memtest.org/)를 이용하여 문제가 없는지 확인할 수 있다. 다만, 검사소요시간이 꽤나 긴 편이었다.
- 그밖의 장치(device) 문제 : Graphic Card, Network Card, Disk(Raid controller) 등 하드웨어 관련된 이슈이다. 물리적으로 불량일 경우도 있겠고, 그를 제어하는 firmware/driver의 문제일수도 있다. 후자의 경우 firwamre/driver update(patch)를 통해 문제를 해결할 수 있으니 관련 change log등을 찾아보자.
- Software 이슈 : kernel이나 그 Module (예를 들어, filesystem의 module), 혹은 특정 process의 문제(bug)일수도 있다. 이 역시 소프트웨어 문제이므로 그와 관련한 bug report, changelog 등을 찾아 update(patch)함으로 해결해야 한다.
원인 분석
위와 같이 hardware/firmware/software 에 걸쳐 발생할 수 있어, 원인을 분석하기가 쉽지 않다.
- 시스템 로그 확인 : 로그는 대부분의 문제를 파악하고 분석하는데 매우 큰 도움을 준다. os(kernel)가 /var/log/messages등의 시스템 로그에 관련 정보(error)를 남기진 않았는지 꼼꼼하게 살펴보자.
- BIOS event log 확인 : hardware의 경우라면 bios event log에 로그가 기록되어 있을 수 있다. bios 상에서 확인 가능하며 각 vendor사 마다 os/web에서 접근하도록 software를 배포하기도 한다.
- kernel crash dump 확인 : kernel이 crash되었을때 메모리를 image로 dump하여 이 dump된 image를 분석할 수도 있다.
위에서 언급했듯, 이 문서는 마지막의 kernel crash dump로 확인하는 방법에 대해 다룰것이다.
crash dump
kexec
kexec를 이용하면 현재 커널에서 BIOS, 부트로더 등을 거치지 않고 새로운 커널로 부팅 할 수 있다. 이는 crash dump에서 매우 중요한 역할을 한다. kernel crash가 발생했을 경우 kexec를 이용하여 새로운 커널(second kernel, capture kernel)로 부팅을 하게 되고, 메모리를 dump하는것이다. 단, kexec를 실행하기 위해선 second kernel이 load될 메모리가 미리 설정되어 있어야 한다.
설치 과정은 아래와 같다.
# apt-get install kexec-tools
# vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="crashkernel=256M"
# update-grub
grub에서의 kernel parameter에 crashkernel을 추가한다. 이제 second kernel은 256M 메모리를 가지고 부팅될 것이다. 메모리는 initrd와 사용하는 kernel module양에 따라서 다르다. 그리고 dump시 필터링을 담당하는 makedumpfile에서 물리적 메모리에 비례(4K당 2bit)하여 사용한다고 한다. 이에 맞게끔 설정해야하니 테스트가 꼭 필요하겠다. 다른 kdump 문서를 보면 crashkernel을 auto로 설정한 경우를 볼수 있는데, 이는 일반 커널일 경우이다. auto라면 기본 128M에서 총 물리메모리의 양에 비례하여 알아서 설정해한다고 한다.
이제 리부팅하여 crashkernel을 예약하자.
# reboot
아래의 명령으로 crashkernel이 잘 잡혀있는지 확인할수 있다.
# cat /proc/cmdline
root=/dev/sda5 ro quiet crashkernel=256M
# grep -i crash /proc/iomem
03000000-0affffff : Crash kernel
이제 kexec를 사용할 환경은 마련되었다. 새로운 커널을 load해보자.
# cat /sys/kernel/kexec_loaded
0
# kexec -l --command-line="root=/dev/sda5 ro quiet" --initrd=/boot/initrd.img-3.16.0-4-amd64 /boot/vmlinuz-3.16.0-4-amd64
# cat /sys/kernel/kexec_loaded
1
보면 알겠지만 bootloader에서 설정한 그대로를 넣으면 된다. kernel과 initrd를 지정하고, kernel parameter를 command-line에 옵션으로 추가한다. load가 정상적으로 진행된다면 /sys/kernel/kexec_loaded가 1로 변경되어 있을것이다.
이제 load된 2nd kernel를 실행해보자.
# kexec -e
정상적으로 실행된다면 콘솔화면으로 2nd kernel로 부팅되는것을 볼수 있다. free 명령으로 memory를 보면 256M로 잡혀있는것을 확인할수 있다.
그러나 위 방법은 panic시 kexec가 수행되지 않는다. kexec로 -l (load)대신 -p (load-panic)을 수행하면 panic시 load될 kernel을 지정할수 있다.
# kexec -p --command-line="root=/dev/sda5 ro quiet" --initrd=/boot/initrd.img-3.16.0-4-amd64 /boot/vmlinuz-3.16.0-4-amd64
# cat /sys/kernel/kexec_crash_loaded
kexec_loaded가 아닌 kexec_crash_loaded로 load여부를 확인할 수 있다. (일반적으로 capture kernel을 load할때 kernel parameter값으로 “irqpoll maxcpus=1”을 추가하도록 권장한다.)
이제 적제된 커널로 부팅해보자. panic시 2nd kernel로 진입되도록 설정했으니 panic을 일으키면 된다. sysrq를 이용한다.
# echo c > /proc/sysrq_trigger
정상적으로 처리된다면 2nd kernel로 부팅되는것을 확인할수 있을것이다. 위처럼 crash로 등록되어 진입할 경우에는 전과 다르게 /proc/vmcore라는 파일이 생성됨을 확인할수 있을것이다. 파일 사이즈는 “총 메모리의 양 - crashkernel(256M)”일 것이다. 이게 memory dump파일이다. 이 파일을 DISK로 복사하면 dumpfile을 얻을수 있다.
사실 위 kexec만으로도 dump는 가능하다. 그런데 kernel panic시 dumpfile을 옮기고 리부팅하는 작업을 직접 수동으로 처리해야한다. 따라서 위 작업을 스크립트로 생성해 놓고 등록해둬야 한다. 대략적으로 아래와 같겠다.
- 부팅시 kexec -p 등록
- 만약 /proc/vmcore가 있다면 (2nd kernel로 진입한다면) 2-1. /proc/vmcore를 다른 partition으로 복사 2-2. reboot -f
kdump-tools
kdump-tools를 사용하면 더 간단히 진행할 수 있다. 즉 kdump-tools는 kexec -p 작업과 dumpfile을 처리하고 reboot하는 작업 등을 설정파일을 이용하여 간단히 설정 할수 있게 도와준다.
# apt-get install kdump-tools
kdump-tools를 설치하게 되면 kexec-tools, makedumpfiles가 dependacy로 걸려있다. kexec-tools는 알겠고, makedumpfiles는? /proc/vmcore에 필터링을 걸수 있게 한다. 즉 용량이 매우 큰 vmcore를 그대로 복사하지 않고, 필요한 부분만 골라 복사하도록 하는 것이다. 이때 filtering 기능에따라 debug kernel이 필요할 수도 있다고 한다. (debug kernel은 dump file을 분석할때도 필요함). 물론 압축을 한다던지 그런 기능들도 모두 포함되어 있다.
# vi /etc/default/kdump-tools
USE_KDUMP=1
#KDUMP_KERNEL=
#KDUMP_INITRD=
KDUMP_COREDIR="/var/crash"
#KDUMP_CMDLINE_APPEND="irqpoll maxcpus=1 nousb systemd.unit=kdump-tools.service"
#DEBUG_KERNEL=
#MAKEDUMP_ARGS="-c -d 31"
위의 설정말고도 많지만 그냥 default를 이용해도 대부분은 정상작동 할것이다. 위처럼 #(comment out)으로 처리했을경우 grub등에서 parsing해와 알아서 등록해준다.
설정에 대한 확인도 kdump-config를 이용하면 편리하다.
# kdump-config show
USE_KDUMP: 1
KDUMP_SYSCTL: kernel.panic_on_oops=1
KDUMP_COREDIR: /var/crash
crashkernel addr:
current state: Ready to kdump
kernel link:
/usr/lib/debug/boot/vmlinux-3.16.0-4-amd64
kexec command:
/sbin/kexec -p --command-line="placeholder root=UUID=bf86b836-d9c9-4e68-8613-cc7ba3c56895 ro quiet irqpoll maxcpus=1 nousb systemd.unit=kdump-tools.service" --initrd=/boot/initrd.img-3.16.0-4-amd64 /boot/vmlinuz-3.16.0-4-amd64
# kdump-config load
[ ok ] loaded kdump kernel.
이제 sysrq를 이용하여 crash를 유발하면 2nd kernel로 진입됨을 확인할수 있다. /proc/vmcore를 /var/crash로 복사하는데 설정값에 따라 아까 언급한 makedumpfiles로 filtering을 걸수도 있다. scp, ftp등으로 원격으로 파일을 복사하게 설정할수도 있다. 위와 같이 설정했다면 /var/crash/YYYYMMDD 디렉토리에 dumpfile을 생성한뒤, reboot을 진행한다.
XEN에서의 crash dump
아래의 내용은 debian jessie(kernel 3.16.7) , xen 4.4에서 테스트를 진행하였다.
DomU의 crash dump
일반적인 Linux와 같이 위와 같이 설정하면 된다. (PVM의 경우 작동하지 않을수 있다. 확인필요)
In guest kexec works for PVHVM/HVM guests but does not work for PV guests. 출처 : https://lists.xen.org/archives/html/xen-devel/2014-04/msg01708.html
그러나 아래와 같이 xen configure파일을 설정하면 훨씬 간편히 처리할 수 있다.
on_crash="coredump-restart"
vm이 crash되었을 경우 coredump를 찍고 restart한다. coredump는 dom0의 /var/xen/dump에 저장된다. makedumpfiles을 이용하여 filtering하지 않으니 VM Memory양만큼 dumpfile이 생성될것이다.
이제 crash 툴로 원인을 분석하면 된다.
Dom0의 crash dump
Dom0의 경우 일반적인 crash dump설정과는 다르다. xen의 경우 xen micro kernel -> Linux(Dom0) Kernel로 부팅이 된다. 자 이럴 경우 crashkernel parameter를 어디에 둬야 할까? 또 kexec load할 kernel은 xen kernel일까? linux kernel일까? 공식문서 (http://xenbits.xen.org/docs/4.4-testing/misc/kexec_and_kdump.txt) 를 참고하면 다 된다고 한다. 즉 아래와 같다.
- first xen kernel -> first linux(dom0) kernel -> (kexec, crash) -> 2nd xen kernel -> 2nd linux kernel
- first xen kernel -> first linux(dom0) kernel -> (kexec, crash) -> 2nd linux kernel
그런데 테스트해본바로는 첫번째경우는 정상적으로 처리되지 않았다. (사실 저 문서가 엄청 오래되었다. 문서대로 진행되는 경우가 한개도 없다;;) 그리고 생각해보면 구지 첫번째와 같이 처리할 이유가 없다. 예약하는 메모리양만 많아질뿐… crashkernel의 경우는 xen커널의 parameter값으로 들어가야한다.
여기서부턴 시행착오가 많았다. 정리된 문서도 없을 뿐더러, 정리된 문서는 죄다 예전 문서여서인지 제대로 실행되지 않았다. 그만큼 오류가 많을수 있다. 참고하길 바란다.
crashkernel 등록
xen kernel의 parameter로 등록하면 된다.
# vi /etc/default/grub
GRUB_CMDLINE_XEN="dom0_max_vcpus=2 dom0_vcpus_pin crashkernel=256M"
# update-grub
생성된 grub.cfg는 아래와 같은 모양새일것이다.
multiboot /boot/xen-4.4-amd64.gz placeholder dom0_max_vcpus=2 dom0_vcpus_pin crashkernel=256M dom0_mem=2G,max:3G
module /boot/vmlinuz-3.16.0-4-amd64 placeholder root=UUID=bf86b836-d9c9-4e68-8613-cc7ba3c56895 ro quiet
module --nounzip /boot/initrd.img-3.16.0-4-amd64
여러 문서들에서 xen 커널의 parameter로 등록하라고 나와있었다. (http://www.gossamer-threads.com/lists/xen/devel/353159 , ) linux(dom0) kernel의 parameter로 설정해보았는데, 정상적으로 2nd kernel이 load되지 않았다. (segmentation fault) crashkernel옵션을 crashkernel=256M@64M와 같이 size@offset으로도 설정할 수 있다. 몇몇 시스템의 경우는 offset을 지정하지 않았을 경우 문제가 된다고 한다. offset은 메모리예약의 시작점이다. offset을 지정하면 해당 사이즈(physical address기준)부터 시작되어 메모리가 예약된다. > On some systems, it might be necessary to reserve memory with a certain fixed offset. If the offset is set, the reserved memory will begin there
linux kernel paramter로 등록하지 않았으니 dom0에서 확인도 달라진다. 예를 들면 /proc/cmdline과 dmesg에는 당연히 관련 메시지가 없을것이다. 이건 xen console에서 확인할 수 있다.
# xl dmesg | grep -i command
(XEN) Command line: placeholder dom0_max_vcpus=1 dom0_vcpus_pin crashkernel=256M dom0_mem=2G,max:3G
# xl dmesg | grep -i kdump
(XEN) Kdump: 256MB (262144kB) at 0x46db29000
그리고 xl info명령으로 확인해보면 total_memory에서 256M가 더 빠져있음을 확인할 수 있다.
kexec-tools 설치
jessie의 공식 repo에 있는 kexec-tools를 설치하였는데, 정상적으로 처리되지 않았다. grub등에서 crashkernel을 먼저 등록하라는 error message만 뜬다. Dom0(linux)의 kexec에선 xen kernel의 parameter로 설정한 crashkernel을 읽어들일수 없는 것이다. 여기서 한동안 진도가 나가지 않았었는데, 간단했다. compile을 진행하니 정상적으로 처리되는것이다. kexec는 내부적으로 xen 관련 소스가 있는데 공식 repo에 있는 package는 이걸 포함하지 않았다. compile시 –with-xen 옵션을 줘야한다. 설치 이후에는 일반적인 kexec-tools와 동일하게 작동했다. kexec -p로 등록, sysrq로 crash 유발, dump 생성, crash로 분석.. 모두 정상적으로 잘 된다.
kdump-tools 설치
kdump에서 또 문제가 발생한다. 오류는 위와 동일하다. crashkernel을 인식못하는 문제이다. kdump에선 아래의 부분을 확인하는데 모두 fail났다.
- /sys/kernel/kexec_crash_loaded 확인 원래 1로 변경되야하는데 Dom0에서는 변경되지 않았다. 이부분은 kexec-tools와 연관있어보이는데, 찾질 못했다.
- /proc/cmdline에서의 crashkernel 인자값 확인 이 부분을 보면 xen에서의 설정을 고려하지 않았음을 알수 있다.
일단 kdump-tools process가 위 문제로 구동되지 않는다. /usr/sbin/kdump-tools를 수정하여 check하는 부분을 주석처리하여 skip하도록 변경하였다.
case "$1" in
test)
DRY_RUN="true"
#check_kdump_support;
locate_debug_kernel;
locate_kdump_kernel;
kdump_load;
kdump_test
;;
show)
DRY_RUN="true"
#check_kdump_support;
kdump_show
;;
load)
#check_kdump_support;
locate_debug_kernel;
locate_kdump_kernel;
kdump_load;
;;
또 하나 발견한 문제는 makedumpfile 부분에서이다. 가상화서버라면 많은 memory를 사용할텐데 이러면 dumpfile도 매울 클것이다. 그런데 다른 모든 VM들의 memory까지 dump할 필요는 없다. makedumpfile manpage를 보니 아래와 같은 설정할수도 있다.
-X Exclude all the user domain pages from Xen kdump's VMCORE, and extracts the part of xen and domain-0. If VMCORE con‐
tains VMCOREINFO for Xen, it is not necessary to specify --xen-syms and --xen-vmcoreinfo. -E option must be speci‐
fied with this option.
Example:
# makedumpfile -E -X /proc/vmcore dumpfile
수동으로 위와 같이 실행해보았는데 결과는 segmentation fault이다……. 2nd kernel을 dom0로 설정해야하는건인가? 아직 이부분은 해결되지 않았다.
issue
일부서버에서 아래와 같은 이슈가 발견되었다. crash시 2nd kernel loading까지 잘 넘어가는데 그 후 바로 kernel panic이 발생하고 진행되지 않았다.
[ 102.721579] SysRq : Trigger a crash
[ 102.725118] BUG: unable to handle kernel NULL pointer dereference at (null)
[ 102.732986] IP: [<ffffffff8136ffc2>] sysrq_handle_crash+0x12/0x20
[ 102.739102] PGD 1719cc067 PUD 1719e0067 PMD 0
[ 102.743616] Oops: 0002 [#1] SMP
[ 102.746891] Modules linked in: openvswitch gre vxlan xen_gntdev xen_evtchn xenfs xen_privcmd nfsd nfs_acl rpcsec_gss_krb5 auth_rpcgss oid_registry nfsv4 dns_resolver nfs lockd sunrpc fscache bridge stp llc intel_powerclamp coretemp crc32_pclmul ghash_clmulni_intel cdc_ether aesni_intel usbnet xfs iTCO_wdt iTCO_vendor_support mii evdev aes_x86_64 ttm lrw drm_kms_helper gf128mul glue_helper ablk_helper cryptd drm lpc_ich serio_raw pcspkr mfd_core shpchp i2c_i801 tpm_tis button tpm i7core_edac ioatdma edac_core processor thermal_sys blktap(O) ipmi_watchdog ipmi_si ipmi_poweroff ipmi_devintf ipmi_msghandler fuse drbd lru_cache libcrc32c autofs4 ext4 crc16 mbcache jbd2 btrfs xor raid6_pq dm_mod md_mod sg sr_mod sd_mod cdrom ata_generic crc32c_intel ata_piix libata lpfc crc_t10dif crct10dif_generic ehci_pci uhci_hcd ehci_hcd megaraid_sas usbcore usb_common crct10dif_pclmul scsi_transport_fc scsi_tgt igb i2c_algo_bit scsi_mod i2c_core crct10dif_common dca ptp pps_core bnx2
[ 102.834663] CPU: 0 PID: 1009 Comm: bash Tainted: G O 3.16.0-4-amd64 #1 Debian 3.16.7-ckt11-1+deb8u5
[ 102.844652] Hardware name: IBM System x3650 M3 -[794552K]-/00D4062, BIOS -[D6E157AUS-1.15]- 06/13/2012
[ 102.853951] task: ffff880171baa190 ti: ffff8801707f8000 task.ti: ffff8801707f8000
[ 102.861427] RIP: e030:[<ffffffff8136ffc2>] [<ffffffff8136ffc2>] sysrq_handle_crash+0x12/0x20
[ 102.869972] RSP: e02b:ffff8801707fbec0 EFLAGS: 00010282
[ 102.875284] RAX: 000000000000000f RBX: ffffffff818a4d20 RCX: 0000000000000000
[ 102.882413] RDX: ffff88017f40eda0 RSI: ffff88017f40d478 RDI: 0000000000000063
[ 102.889546] RBP: 0000000000000063 R08: 0000000000000437 R09: ffffffff81a6e0fc
[ 102.896675] R10: 0000000000000437 R11: 0000000000000003 R12: 0000000000000000
[ 102.903804] R13: 0000000000000004 R14: 0000000000000001 R15: 0000000000000000
[ 102.910936] FS: 00007fde82297700(0000) GS:ffff88017f400000(0000) knlGS:0000000000000000
[ 102.919019] CS: e033 DS: 0000 ES: 0000 CR0: 000000008005003b
[ 102.924763] CR2: 0000000000000000 CR3: 0000000172955000 CR4: 0000000000002660
[ 102.931894] Stack:
[ 102.933913] ffffffff8137067c 0000000000000002 0000000000e2e408 0000000000000002
[ 102.941390] ffff8801707fbf58 ffffffff81370b1b ffff880171406640 ffffffff81206919
[ 102.948866] ffff8801707fbf58 ffff8801715a7500 ffffffff811a8212 ffff8800028bbe00
[ 102.956344] Call Trace:
[ 102.958798] [<ffffffff8137067c>] ? __handle_sysrq+0xfc/0x160
[ 102.964541] [<ffffffff81370b1b>] ? write_sysrq_trigger+0x2b/0x30
[ 102.970636] [<ffffffff81206919>] ? proc_reg_write+0x39/0x70
[ 102.976297] [<ffffffff811a8212>] ? vfs_write+0xb2/0x1f0
[ 102.981609] [<ffffffff811a8d52>] ? SyS_write+0x42/0xa0
[ 102.986833] [<ffffffff8151168d>] ? system_call_fast_compare_end+0x10/0x15
[ 102.993705] Code: f8 ff ff 44 01 ed 41 39 6c 24 34 75 de 4c 89 e7 e8 24 f8 ff ff eb d4 66 90 66 66 66 66 90 c7 05 c5 57 6f 00 01 00 00 00 0f ae f8 <c6> 04 25 00 00 00 00 01 c3 0f 1f 44 00 00 66 66 66 66 90 53 8d
[ 103.013988] RIP [<ffffffff8136ffc2>] sysrq_handle_crash+0x12/0x20
[ 103.020188] RSP <ffff8801707fbec0>
[ 103.023678] CR2: 0000000000000000
[ 103.027077] ---[ end trace 9e2de84d1f3c78f2 ]---
[ 103.031795] Kernel panic - not syncing: Fatal exception
[ 103.042388] Kernel Offset: 0x0 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffff9fffffff)
[ 0.000000] do_IRQ: 0.124 No irq handler for vector (irq -1)
[ 0.003389] do_IRQ: 0.172 No irq handler for vector (irq -1)
[ 0.616731] ERST: Can not request [mem 0x7f6ef000-0x7f6f0bff] for ERST.
Loading, please wait...
[ 1.027158] Kernel panic - not syncing: Can not allocate SWIOTLB buffer earlier and can't now provide you with the DMA bounce buffer
[ 1.039064] CPU: 0 PID: 63 Comm: systemd-udevd Not tainted 3.16.0-4-amd64 #1 Debian 3.16.7-ckt11-1+deb8u5
[ 1.048625] Hardware name: IBM System x3650 M3 -[794552K]-/00D4062, BIOS -[D6E157AUS-1.15]- 06/13/2012
[ 1.057927] ffff880476753aa8 ffffffff8150b4c5 ffffffff8174ad60 ffffffff8150831d
[ 1.065395] 0000000000000008 ffff880476753ab8 ffff880476753a58 0000005000000000
[ 1.072864] 0000000000000000 0000000000000000 0000000000001000 0000000000000002
[ 1.080333] Call Trace:
[ 1.082781] [<ffffffff8150b4c5>] ? dump_stack+0x41/0x51
[ 1.088094] [<ffffffff8150831d>] ? panic+0xc8/0x1fc
[ 1.093060] [<ffffffff812cdfbd>] ? swiotlb_tbl_map_single+0x2bd/0x2c0
[ 1.099588] [<ffffffff81185ccd>] ? alloc_pages_current+0x9d/0x150
[ 1.105768] [<ffffffff812ce6f5>] ? swiotlb_alloc_coherent+0xd5/0x140
[ 1.112207] [<ffffffffa0364b79>] ? uhci_start+0x139/0x5b8 [uhci_hcd]
[ 1.118648] [<ffffffffa0232154>] ? usb_add_hcd+0x2f4/0x870 [usbcore]
[ 1.125089] [<ffffffffa0243a49>] ? usb_hcd_pci_probe+0x189/0x530 [usbcore]
[ 1.132048] [<ffffffff812e2fbf>] ? local_pci_probe+0x3f/0xa0
[ 1.137792] [<ffffffff812e42aa>] ? pci_device_probe+0xda/0x130
[ 1.143710] [<ffffffff813a2d9d>] ? driver_probe_device+0x9d/0x3d0
[ 1.149890] [<ffffffff813a319b>] ? __driver_attach+0x8b/0x90
[ 1.155635] [<ffffffff813a3110>] ? __device_attach+0x40/0x40
[ 1.161378] [<ffffffff813a0e9b>] ? bus_for_each_dev+0x5b/0x90
[ 1.167211] [<ffffffff813a2430>] ? bus_add_driver+0x180/0x250
[ 1.173045] [<ffffffffa036b000>] ? 0xffffffffa036afff
[ 1.178184] [<ffffffff813a38eb>] ? driver_register+0x5b/0xe0
[ 1.183929] [<ffffffffa036b0c3>] ? uhci_hcd_init+0xc3/0x1000 [uhci_hcd]
[ 1.190629] [<ffffffff8100213c>] ? do_one_initcall+0xcc/0x200
[ 1.196463] [<ffffffff810daeca>] ? load_module+0x20da/0x26b0
[ 1.202207] [<ffffffff810d6ab0>] ? store_uevent+0x40/0x40
[ 1.207693] [<ffffffff810db5fd>] ? SyS_finit_module+0x7d/0xa0
[ 1.213527] [<ffffffff8151168d>] ? system_call_fast_compare_end+0x10/0x15
[ 1.220404] Kernel Offset: 0x0 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffff9fffffff)
[ 1.230574] ---[ end Kernel panic - not syncing: Can not allocate SWIOTLB buffer earlier and can't now provide you with the DMA bounce buffer
특이한점은 kexec -l로 loading후 kexec -e로 excute하면 정상적으로 2nd kernel 구동이 가능했다. crashkernel로 진입할 때가 문제인듯 보인다.
아래와 같이 crashkernel의 주소(offset)를 manual로 설정하니 정상적으로 작동했다. offset을 설정하므로 kdump로 예약되는 물리주소가 fix하게 변경됨을 확인할수 있다.
# xl dmesg | grep -i crashkernel
placeholder dom0_max_vcpus=4 dom0_vcpus_pin crashkernel=256M@64M dom0_mem=4G,max:5G crashkernel=256M@64M
# xl dmesg | grep -i kdump
(XEN) Kdump: 256MB (262144kB) at 0x4000000
이처럼 시스템에 따라 kdump가 제대로 작동하지 않을수 있다. kdump 설정을 한뒤에는 crash를 유발하여 꼭 테스트를 진행해봐야 할 듯 하다.
DNS container 부하 시험
목적
- DNS query를 여러 개의 DNS containers가 처리할 수 있도록 부하 분산 처리 방법 고안
- 부하분산기(Load Balancer) 하단의 container 개수를 1개부터 증가시켜 가면서 QPS(queries per second)를 측정하여 하나의 물리 서버에 최대 DNS container 개수 파악
OS 설치를 위한 raid 구성
OS를 설치할 때 매번 고민하게 되는게 raid 구성이다. 물론 별도의 RAID Controller가 있다면 큰 고민하지 않지만 없을 경우 멈칫 고민하게 된다. 요즘 대부분의 메인보드의 칩셋이 자체적으로 raid를 지원한다. 이 onboard의 raid를 이용하는게 좋은가? 아니면 os(linux)에서의 softraid를 이용하는게 좋은가? swap partition은 raid를 구성하는게 나은가? ssd는 어떻게 raid를 구성해야할까? 그 고민을 줄이기 위해 정리하였다.
RAID 종류
raid 종류는 크게 3개로 나눌수 있을듯하다.
- Hardware RAID : 별도의 RAID Card로 구성하는 방법. 단점이라고는 비싼 가격이뿐이다. performance, 안정성 모두 best. 이 Raid Card에 HDD들이 연결되어 있어, OS에서는 RAID Controller의 driver없이 HDD를 볼수(access할수) 없다. 부팅 과정중 별도의 Setup툴로 구성한다.
- Onboard RAID : 메인보드의 칩셋(예를들어 intel, jmicron, nvidia)에서 지원하는 Raid Controller로 구성하는 방법. 그런데 raid에 사용되는 실질적인 모든 연산은 hardware가 아닌 software를 이용한다. 그렇기에 onboard raid가 아닌 fake raid라고 더 많이 불리운다.
- Software RAID : 별도의 하드웨어 도움없이 온전히 OS에서 software로 처리하는 raid 방법.
fake raid vs. software raid
hardware-assited software raid, fake raid 불리우는 까닭은 onboard chipset(즉 hardware)의 역할이 매우 작다는데 있다. 마치 별도의 hardware가 raid 전부를 제어할 것 같이 보이지만, 실질적으론 software(linux에서는 dmraid)가 대부분은 담당한다고 한다. 그래서 패리티 연산이 있는 raid 5,6등은 아예 지원하지 않은 경우가 대부분이고(오직 raid 0,1만 지원), 있다하더라도 CPU의 부하가 커서 사용하지 않는다고 한다. 게다가 software raid(mdadm)과 다르게 chipset의 vendor에 귀속적이다. 그럼 performance는? 구글링해보면 performance를 비교해놓은 글들이 많은데, 대체적으로 큰 차이는 없어보인다. (물론 chipset이 계속 발전하다보면 또 어떨지 모르지만) 이래서인지 대부분 fake raid보다 software raid를 권한다.
참고로 linux에서 보통 fake raid는 dmraid(혹은 mdadm), software raid는 mdadm를 이용하여 구성한다. 헷갈리게 fake raid가 boot과정중 setup이 가능해 마치 os에서 접근못할것 같지만 아니다. 즉 raid로 묶어도 각 disk는 os에서 보인다. 물론 software raid도 마찬가지. fake raid와는 달리 software raid는 raid 5,6등도 설정이 가능은하지만 CPU에 부하가 많기에 피하는것이 좋다고 한다.
정리하면 아래와 같다.
- onboard raid(fake raid)보다 software raid(mdadm)을 이용하자.
- software raid도 raid 5,6은 되도록 피하자.
swap 구성
mdadm을 이용하여 raid를 구성할 경우, swap 파티션의 raid도 고민할 필요가 있다. 일반적인 경우라면 os partition은 redundancy를 위해 mirror를 포함하여 구성하게 된다. (raid 1,10 등) 즉, 디스크(위의 경우 partition)가 문제가 발생할 경우에도 데이터 소실을 방지하고 지속적인 운영을 대비하기 위함이다.
그런데 swap의 경우는 가상 메모리(휘발성)이므로 데이터의 소실을 걱정할 필요가 없다. 오히려 mirror로 구성했을 경우 불필요한 데이터를 2중으로 기록하기에, 디스크의 수명만 단축시킬 뿐이다. 그렇다고 raid 0(stripe)으로 구성한다면, 디스크 둘 중 하나라도 문제가 발생했을 때 아예 사용할수 없게 될것이다. 따라서 이 경우엔 raid 구성없이 진행 하는것이 낫다.
pair disk 구성으로 2개의 parition을 사용한다면, 그냥 2개의 swap partition을 구성하면 된다. 총 swap size는 2개의 partition을 더한 값이 될것이고, linear하게 사용되여 첫번째 swap partition이 꽉 차게되면 2번째 swap partition이 사용될 것이다.
ssd의 raid 구성
HDD와 달리 SSD는 매체 특성상 데이터를 바로 덮어쓰기(rewrite)할 수 없다. 다시 쓰려면 반드시 삭제(erase)의 과정이 필요하다. 그런데 SSD는 셀당 쓰기수명(정확히는 삭제)이 있어, 특정 영역에 반복해서 자주 쓰는 작업이 있다면 수명이 다해 더이상 쓰기가 불가능해 진다. OS처럼 한번 write하면 계속 읽기만 하는 영역 있는 반면, 데이터 영역의 경우는 쓰기는 빈번할 것이다. 이럴 경우 raid mirror로 구성한다면 디스크 수명에 치명적이지 않을까?
SSD는 이런 이슈를 위해 여러 방법(wear leveling)을 사용한다고 한다. 해당 셀의 삭제 회수를 저장하여 사용이 적은 셀에 저장하게 하고(counting), 이미 사용한 영역(위의 OS영역와 같은)들의 데이터도 쓰기 회수가 많은 영역과 데이터를 옮기고(swapping)등 수명 향상을 위한 controller의 기능들이 있다. 그렇다곤 해도 현재로선 HDD와 비교했을때 수명은 짧다.
그리고 저장방식(TLC, MLC, SLC)에 따라 재기록 가능 회수가 다르다. 위의 controller 기능들과 SSD 저장방식을 염두해두고 raid를 구성하도록 하자.
그밖의 RAID를 대체(alternative)할수 있는 것들
- lvm lvm으로 자체적인 raid 구성이 가능하다. 또한 kernel의 backend로 동일한 md(multiple device) driver를 사용하여, performance 역시 거의 동일하다고 한다. lvm이나 mdadm이나 관리자가 익숙한 인터페이스를 사용해도 무방할 듯 보인다. 다만 프로그램의 성격상 lvm보단 mdadm이 raid 자체 이슈 대한 user support가 많다. raid 관련 이슈가 발생했을 경우 인터넷에서 찾는 정보양은 mdadm이 lvm보다 훨씬 많다.
- btrfs (zfs) brtfs나 zfs(linux)같은 최근의 filesystem의 경우 자체적으로 raid의 구성이 가능하다. 다만 mdadm과의 비교 자료들을 보면 아직까진 CPU 부하나 Performance면에서 떨어지는 편이다. 게다가 최신의 OS가 아니라면 grub, initramfs에 해당 모듈이 없을 가능성이 크다. 그러나 스냅샷, 서브 볼륨(volume 혹은 pool), IO 향상을 위한 압축 등의 기타 여러가지 기능들은 매력적이다. 이런 기능들과 함께 자체 raid를 구성하고 싶다면 development용으로 구성해볼만 하다.
결론
- 별도의 raid controller가 없다면 softraid로 구성하자.
- softraid 구성은 아직까지 여러면에서 mdadm이 좋다.
- swap partition은 mirroring 하지 않는 것이 좋다.
- ssd는 hdd와 비교했을때 쓰기 수명이 짧다. raid 구성시 유지비(교체 비용)를 고려하자.
간단해보이는 raid 구성에도 고려해야 할것이 많다. 벤더의 종속, 매체의 특성, 파티션의 성격, 기술의 적합성 등등… 한번 적용하면 되돌리기 어려우니, 또 다른 고려사항은 없는지 충분히 고민해보고 적용하도록 하자.
osticket
- http://osticket.com
- 세계적으로 가장 인기있는 고객 지원 티켓 시스템
- GPL 라이센스로 무료로 다운로드하여 설치 할 수 있다.
서비스 특징
- 효율적인 기술지원 및 장애처리를 위하여 해당 서비스 도입
- 작업 처리 진행사항 및 작업 히스토리 관리에 효율
- 티켓 발급 후 담당자를 지정하여 체계적인 업무 처리 가능
- 티켓 현황 그래프 분석 및 레포트 기능
- 메일 pop3/smtp 기능으로 자동 티켓 변환 및 자동 메일 알림 발송
- 고객 포털 사이트 제공하여 처리 현황을 포탈에서 확인 가능
설치
홈페이지상에는 웹서버에 종류와 버젼은 나와 있지 않다.
php 5.3(or better) , mysql 5(or better) 버젼이어야만 한다고 한다.
apache 2.2 + php 5.3 + mysql 5.5 버젼으로 설치를 진행하였다.
debian version : 7.0
application install
# apt-get install nginx mysql-server php5 php5-mysql php5-imap php5-gd``osticket source download : http://osticket.com/download 최신 버젼으로 다운을 받는다. 다운로드시 이름과 이메일 주소를 입력해야 된다.
다운을 받은 뒤 설치할 서버에 전송한다.
# scp ./osTicket-v1.9.12.zip test:/var/wwwosticket 웹경로를 설정한 뒤 압축 해제
# mkdir /var/www/osticket # cd /var/www # unzip osTicket-v1.9.12.zip -d ./osticket
apache vhost 설정 파일 수정
<VirtualHost *:80> ServerAdmin webmaster@localhost ServerName ticket.iorchard.co.kr DocumentRoot /home/web/osticket/upload <Directory /> Options FollowSymLinks AllowOverride None </Directory> <Directory /home/web/*> Options Indexes FollowSymLinks MultiViews AllowOverride None Order allow,deny allow from all </Directory> ScriptAlias /cgi-bin/ /usr/lib/cgi-bin/ <Directory "/usr/lib/cgi-bin"> AllowOverride None Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch Order allow,deny Allow from all </Directory> ErrorLog ${APACHE_LOG_DIR}/error.log # Possible values include: debug, info, notice, warn, error, crit, # alert, emerg. LogLevel warn CustomLog ${APACHE_LOG_DIR}/access.log combined </VirtualHost>config file 생성
# cd /var/www/osticket/upload/include # cp ost-sampleconfig.php ost-config.php # chmod 666 ost-config.php
database 생성
# mysql -u root -p mysql> create database osticket; mysql> create user osticket@localhost identified by '패스워드'; mysql> grant all privileges on osticket.* to osticket@localhost identified by '패스워드'; mysql> flush privileges; mysql> quit
웹 접속(http://ticket.iorchard.co.kr) 하여 필요한 정보 입력 후 설치 마무리
기능
관리자 페이지로 접속하게 되면 메뉴가 여러가지가 보이지만 두가지 패널로 나뉘게 된다.
Admin Panel 전반적인 관리자 설정과 이메일 설정 그리고 티켓을 처리 할 agents를 생성 및 관리 할 수 있다. Dash Board 시스템 로그와 서버 설치 정보를 확인 가능 Settings 회사 정보 설정 및 디폴트 메일 설정, 접속 인증 설정 등등 다양한 설정을 셋팅 Manage 티켓 필터 설정 및 SLA 설정, 티켓 주제를 설정하여 사용자가 주제에 맞게 선택하여 티켓을 발급 할 수 있음 Emails osticket에 사용 될 이메일 주소를 추가 삭제 수정 할 수 있음. pop3/smtp 설정으로 자동 티켓 발급 기능 설정 가능 Agents 티켓을 처리할 agents(엔지니어)를 추가할 수 있고 부서와 팀을 지정하여 체계적인 운영을 할 수 있음 Agent Panel 티켓 현황 및 진행사항을 확인 할 수 있으며 회원 정보 등을 관리 할 수 있다. Dash Board 티켓 현황을 그래프로 확인 할 수 있고 자신의 agent 정보를 직접 수정을 할 수 있음 Users 회원 정보를 추가, 수정, 삭제, 인증 등등 모든 고객 설정을 관리, 기업을 추가하여 고객별로 분류 가능 Tickets 티켓 현황 및 진행사항을 이곳에서 확인이 가능하며 처리 내용을 이곳에서 작성하게 되면 처리 과정을 단계별로 확인 가능 Knowledgebase FAQ 를 주제별로 등록 할 수 있다. 현재는 UVDI와 UXEN에 대한 SOP가 작성되어 회원들이 포털에 로그인하게 되면 연락 가능
Admin Panel 최초 접근시 setup/install 디렉토리를 보안상의 이유로 삭제하라는 메시지가 뜬다. 하지만 해당 디렉토리가 없다. setup 디렉토리를 다른 이름으로 변경한다.
두번째 메시지가 또 뜨게 된다. config file 에 쓰기 권한을 제거하라는 메시지이다. 권한 설정을 변경하여 준다.
# cd /var/www/osticket/upload # mv setup setup.bak # chmod 644 include/ost-config.php``
이메일 설정
발신
기본 이메일 설정은 “admin panel -> setings -> emails” 메뉴에서 설정이 가능하다. template email과 alert email 주소를 목록에 있는 이메일 주소로 지정하여 선택하여야 한다. 신규 메일 주소를 추가하려면 “admin panel -> emails -> add new email” 에서 추가가 가능하며 별도 smtp 서버를 지정하여 설정할 수 있다.
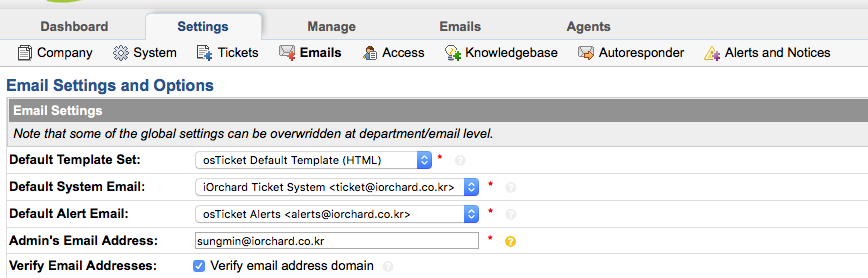
- Default Template Set : 이메일 템플릿 형식을 지정한다. 현재 default 로 “admin panel -> emails -> templates” osticket default template(html) 지정되어 있다.
- Default System Email : osticket system에서 발송되는 메일을 지정한다. 해당 메일 주소로 사용자들에게 전달되는 티켓 메일 등 전반적인 메시지가 발송된다.
- Default Alert Email : 로그인 실패 및 기타 경고 메시지를 발송하는 이메일 주소를 지정한다.
- Admin’s Email Address : 관리자의 이메일 주소를 입력한다.
수신
별다른 수신 서버 설정이 되어있지 않다면 사용자들은 티켓 발급시 유저포털 페이지에서 티켓을 발급하여야 한다. osticket에서는 imap, pop 기능을 지원하여 수신 서버를 설정하여 해당 서버로 수신되는 메일을 티켓으로 변환 할 수 있다. 설정 방법은 메일 주소를 관리하는 “admin panel -> emails” 탭에서 수신 설정을 할 메일 주소를 클릭한다. 아래는 ticket@iorchard.co.kr(default system email) 주소를 pop 그리고 smtp 설정을 한 예문이다.
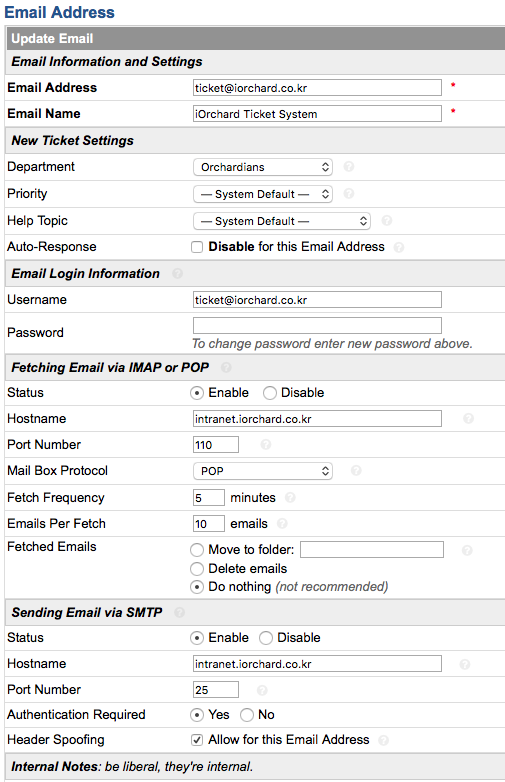
티켓 발급
티켓을 발급하는 방법은 2가지이다. 첫번째는 유저 포털페이지에서 로그인을 한뒤 티켓을 발급하는 방법, 두번째는 이메일로 간단하게 티켓을 발급하는 방법이 있다. 이메일로 티켓을 변환하여 발급을 하려면 위와 같이 imap, pop 설정을 해야만 한다.
유저 포털 페이지
사용자는 유저 포털 페이지(http://ticket.iorchard.co.kr)에 접속하여 신규 계정을 생성해야 한다. 이메일 주소를 입력해야하는데 계정 생성 후 작성한 이메일 주소로 링크가 걸린 주소가 발송이 되며 해당 주소를 클릭하게 되면 포털 페이지로 이동이 되며 계정 인증에 성공한다. 계정 승인은 관리자 페이지에서도 물론 가능하다.
승인이 이루어지면 로그인이 가능하고 티켓을 발급할 수 있다.
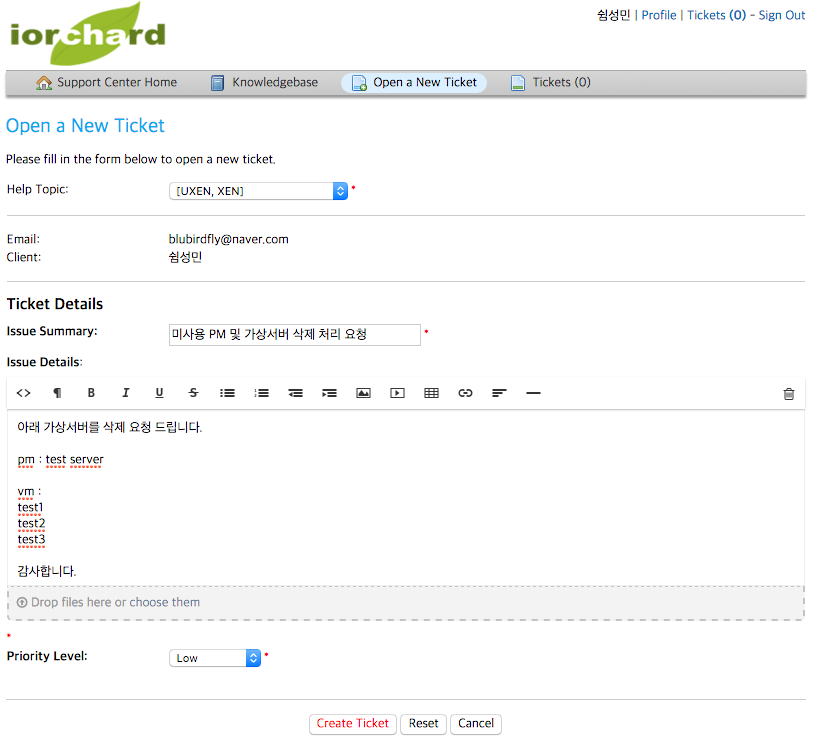
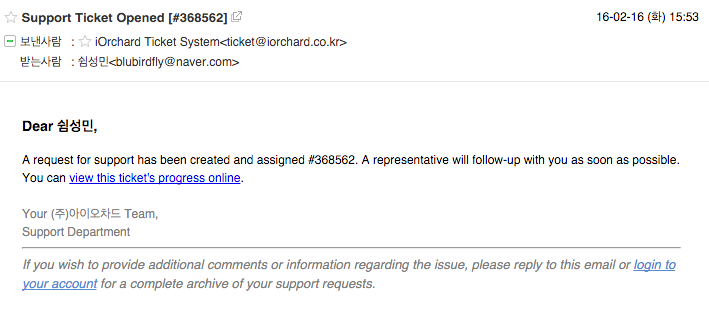
티켓을 발급하게 되면 사용자 이메일로 정상적인 발급이 이루어졌다는 메시지와 티켓 처리 현황을 볼 수 있는 포털 페이지 링크가 함께 발송된다.
이메일
이메일 티켓 발급은 간단하다. 위에 나와있는 imap/pop 설정으로 메일서버에 계정 정보를 입력하여 등록하게 되면 해당 계정으로 메일 발송시 자동으로 티켓으로 변환이 되어 관리자 페이지에서 확인이 가능하다.
현재 pop 설정이 되어진 default system email(ticket@iorchard.co.kr)로 이메일을 발송하여 작업 요청을 하였다.
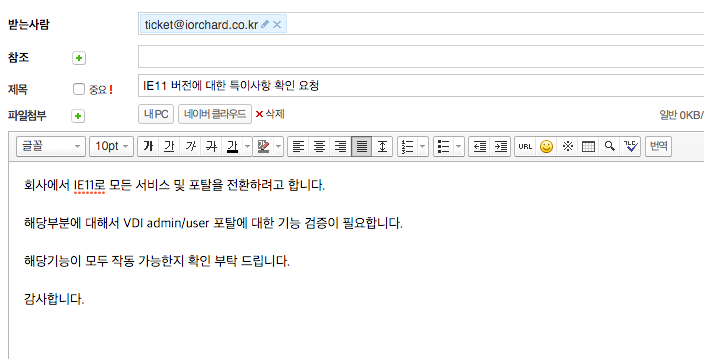
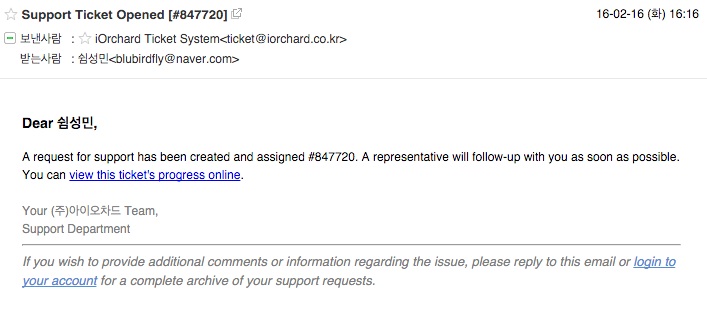
포털 페이지로 티켓을 발급 하였을때와 마찬가지로 사용자 이메일로 티켓 발급 관련 메일이 발송되어진다.
티켓 처리
사용자에게 발급되어진 티켓은 관리자 페이지에서 처리 해야 한다. “관리자 페이지 -> agent panel -> tickets”에서 티켓 상황을 확인 할 수 있다. 위에서 사용자 포털페이지 및 이메일로 발송되어진 티켓이 보여진다.
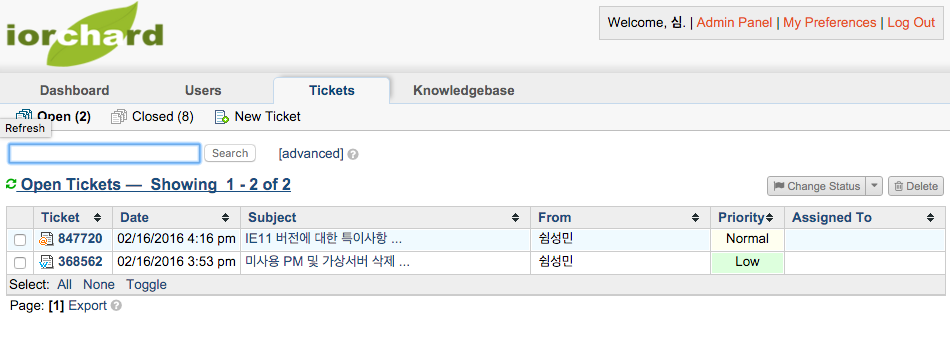
처리해야 될 티켓을 선택하여 post reply 탭에서 작업 처리 내용을 작성한다. 작업이 완료되었다면 티켓의 상태를 open -> resolved 로 변경하여 준다.
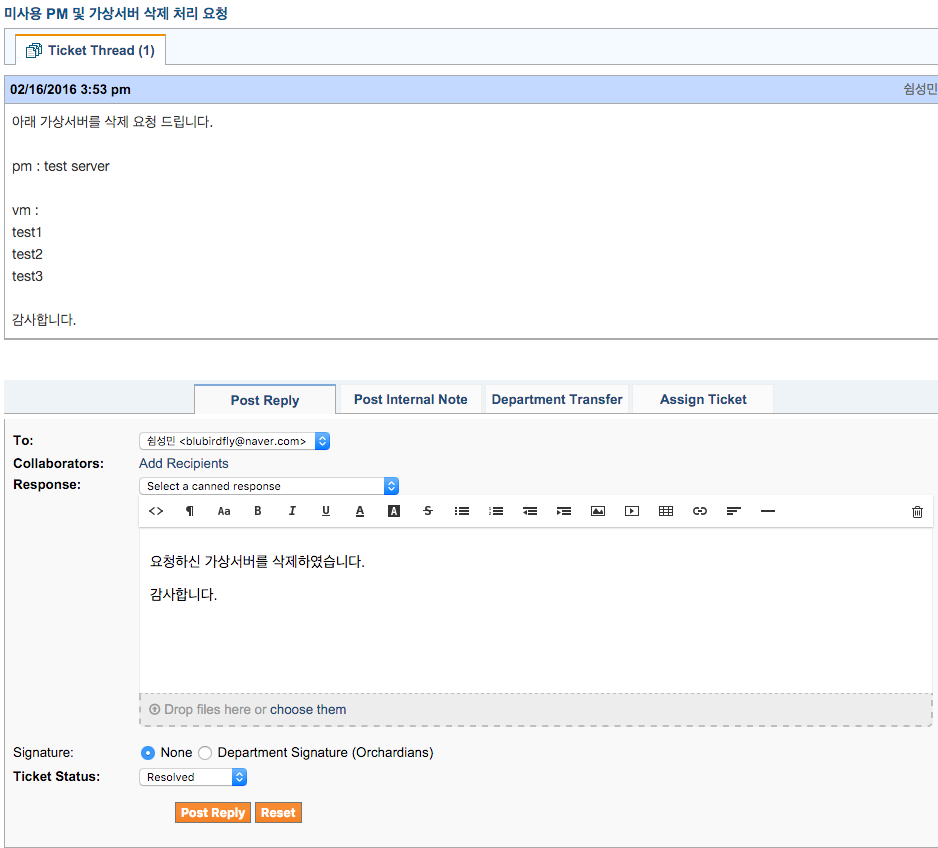
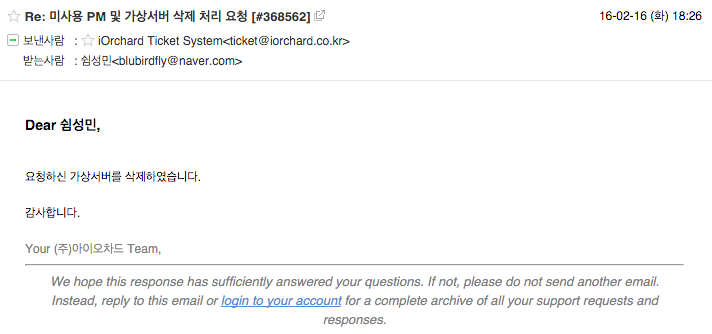
답변되어진 작업 처리 내용은 사용자에게 메일로 발송 되어진다.
VM 코어덤프 분석 (비정상적인 시스템 종료)
1. crash에서 log 분석
log 명령의 실행 결과 아래와 같이 BUG: unable to handle kernel NULL pointer dereference at 0000000000000008 메시지를 확인함.